搜索之单词接龙[Langur Monkey]

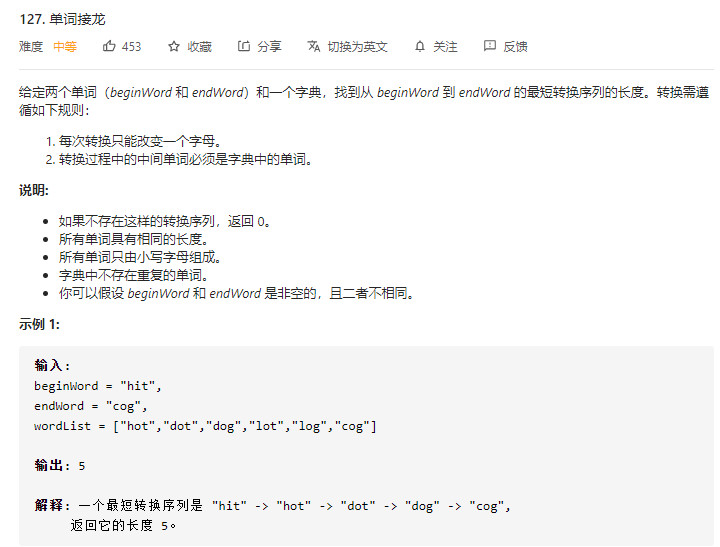
- 单词之间的可以组成一张图,图的顶点为单词本身,单词之间的连接线表示单词之间的转换关系,单向箭头表示一个方向转换,双向箭头表示双向切换,题目要求的从$beginWord$到$endWord$,的最短路径,可以使用$BFS$的搜索方法解决
- 如上图所示,可以找到两条路径:
hit->hot->dot->dog->cog
hit->hot->lot->log->cog
方法1:BFS
- 准备一个
transform(Set<String> words, String word)函数,生成的是与当前word差距一个字符的单词,此单词存在于words中,返回的是个List - 准备一个
Queue,与记录到达endWord的步数steps,一开始将beginWord推进Queue,steps=1 - 当
Queue不为空,for loop当前的size,弹出元素记为cur,通过transform获取到潜在的单词- 如果潜在单词有
endWord,返回steps - 如果潜在单词没有
endWord,将当前的潜在单词推进Queue - 每一层的
while循环steps+1表示走了几个单词
- 如果潜在单词有
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
if (wordList == null || wordList.size() == 0 || !wordList.contains(endWord)) return 0;
Queue<String> queue = new LinkedList<>();
Set<String> words = new HashSet<>(wordList);
queue.offer(beginWord);
int steps = 1;
while (!queue.isEmpty()) {
int size = queue.size();
steps++;
for (int i = 0; i < size; i++) {
String cur = queue.poll();
List<String> candidates = transform(words, cur);
for (String candidate : candidates) {
if (candidate.equals(endWord)) return steps;
queue.offer(candidate);
}
}
}
return 0;
}
/**
* 生成目标的word的所有潜在的word,
* 如hit -->ait bit ...zit但是排除了hit本身
* hit --> hat hbt... hzt但是排除了hit本身
* words 含有的上面生成的潜在的word进行收集
*
* @param words
* @param word
* @return
*/
private List<String> transform(Set<String> words, String word) {
List<String> resList = new ArrayList<>();
StringBuffer sb = new StringBuffer(word);
for (int i = 0; i < sb.length(); i++) {
char tmp = sb.charAt(i);//记录下索引位置下的char,下面的for loop中会剔除掉这个
for (char c = 'a'; c <= 'z'; c++) {
if (tmp == c) continue;//word本身
sb.setCharAt(i, c);//改变i的值
String canditate = sb.toString();
//如果words含有canditate,将其加入到结果集中
if (words.remove(canditate)) resList.add(canditate);
}
sb.setCharAt(i, tmp);//结束本轮loop后,恢复原样
}
return resList;
}
方法2:双向BFS
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
Set<String> wordSet = new HashSet<>(wordList);
if (!wordSet.contains(endWord)) return 0;
Set<String> beginSet = new HashSet<>();
Set<String> endSet = new HashSet<>();
Set<String> visitdSet = new HashSet<>();
beginSet.add(beginWord);
endSet.add(endWord);
int steps = 1;
while (!beginSet.isEmpty() && !endSet.isEmpty()) {
if (beginSet.size() > endSet.size()) {
Set<String> tmpSet = beginSet;
beginSet = endSet;
endSet = tmpSet;
}
Set<String> tmpSet = new HashSet<>();
System.out.printf("beginSet:%s\n", JSON.toJSONString(beginSet));
System.out.printf("endSet:%s\n", JSON.toJSONString(endSet));
for (String word : beginSet) {
char[] chas = word.toCharArray();
for (int i = 0; i < chas.length; i++) {
char src = chas[i];
for (char c = 'a'; c <= 'z'; c++) {
if (c == src) continue;
chas[i] = c;
String nextWord = String.valueOf(chas);
//已经找到了
if (endSet.contains(nextWord)) {
return steps + 1;
}
//没有被访问过,且单词在wordSet中,添加进tmpSet ,本轮结束后赋值给beginSet
if (!visitdSet.contains(nextWord) && wordSet.contains(nextWord)) {
tmpSet.add(nextWord);
visitdSet.add(nextWord);
}
}
chas[i] = src;
}
}
beginSet = tmpSet;
steps++;
}
return 0;
}
文档信息
- 本文作者:wat1r
- 本文链接:https://wat1r.github.io/2020/09/27/word-ladder/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)